Roku Developer Program
Join our online forum to talk to Roku developers and fellow channel creators. Ask questions, share tips with the community, and find helpful resources.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Roku Community
- :
- Developers
- :
- Roku Developer Program
- :
- XML Orphaned Text
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
wlwest82
Visitor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2014
09:06 AM
XML Orphaned Text
I'm having trouble getting some text out of parsed XML. For the most part, everything I need is visible as I walk through the xml, but in the following instance, I can't get to the text. Let's say I have an object Parser (type roXMLElement), and a string xml which contains the following:
After parsing this as Parser.Parse(xml), Parser.tag1@class would return "class1", Parser.tag1.a@href would return "http://www.google.com", and Parser.tag1.a.getText() would return "Google!". The problem I'm having is getting to the "Some more text goes here". I thought that using Parser.tag1.getText() would return that, but it's returning empty. Am I doing this correctly? Is there a way to get to that text?
<xml>
<tag1 class="class1">
<a href="http://www.google.com">Google!</a>
Some more text goes here
</tag1>
</xml>
After parsing this as Parser.Parse(xml), Parser.tag1@class would return "class1", Parser.tag1.a@href would return "http://www.google.com", and Parser.tag1.a.getText() would return "Google!". The problem I'm having is getting to the "Some more text goes here". I thought that using Parser.tag1.getText() would return that, but it's returning empty. Am I doing this correctly? Is there a way to get to that text?
13 REPLIES 13
joetesta
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
03:55 PM
Re: XML Orphaned Text
I bet you can get it if you put another wrapper around it; assuming you need to maintain html compatibility I'd use <span>
and see if you can get it with Parser.tag1.span.getText()
<xml>
<tag1 class="class1">
<a href="http://www.google.com">Google!</a>
<span>Some more text goes here</span>
</tag1>
</xml>
and see if you can get it with Parser.tag1.span.getText()
aspiring
EnTerr
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
06:04 PM
Re: XML Orphaned Text
"joetesta" wrote:
I bet you can get it if you put another wrapper around it; assuming you need to maintain html compatibility I'd use <span>
No, the question was how to work with the XML as given, not to mangle it server-side. The example is a well-formed XML (i fed it to validator just to be sure) and as such would parse and all content should be available. Question is, how to reach that "Some more text goes here" via roXML* APIs?
I subscribed the topic the other day, thinking there is obvious answer i can learn from. XML elements may contain any text or other elements, or mixture of text and elements in any order; that much i know. But how do we eat it? Time for a lifeline: Ask-the-Expert
TheEndless
Channel Surfer
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
06:23 PM
Re: XML Orphaned Text
I don't think there's any way to get orphaned text. I tested this, and while it parses successfully, when you output it with xml.GenXml(False), the orphaned text is gone, so it seems the parser is losing it.
My Channels: http://roku.permanence.com - Twitter: @TheEndlessDev
Instant Watch Browser (NetflixIWB), Aquarium Screensaver (AQUARIUM), Clever Clocks Screensaver (CLEVERCLOCKS), iTunes Podcasts (ITPC), My Channels (MYCHANNELS)
Instant Watch Browser (NetflixIWB), Aquarium Screensaver (AQUARIUM), Clever Clocks Screensaver (CLEVERCLOCKS), iTunes Podcasts (ITPC), My Channels (MYCHANNELS)
EnTerr
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
06:58 PM
XML Offal Text
i just checked how this will be done in Python - it would be to ask for the .tail of the <a> element, like so:
Simplifying the BRS example even more:
PS. in sample python libraries, "foo" will be made .text to <xml/>, "qux" is .tail to <tag/>, all is preserved/accessible.
PPS. i can think of alternative representation too, in which <xml/> will have 3 children, [0] being the string "foo" (or element with empty getName and "foo" as getText), then [1] is <tag> as usual, [2] the "qux" text (string or another empty tag). Then ifXMLElement.getText() will have to be clarified to "returns the first text contained in the element". This is less hacky and more to the spirit of xml but likely requires more changes in parser and may surprise some existing BRS code that is very stuck up on the sequence list it gets from getChildElements().
>>> import xml.etree.ElementTree as et
>>> e = et.fromstring('<xml> <tag1 class="class1"> <a href="http://www.google.com">Google!</a> Some more text goes here </tag1> </xml>')
>>> e
<Element xml at 442968>
>>> e[0]
<Element tag1 at 4427d8>
>>> e[0][0]
<Element a at 4429b8>
>>> e[0][0].tail
' Some more text goes here '
>>> et.tostring(e[0][0])
'<a href="http://www.google.com">Google!</a> Some more text goes here '
Simplifying the BRS example even more:
BrightScript Debugger> x = CreateObject("roXMLElement")
BrightScript Debugger> x.parse("<xml> foo <tag> bar </tag> qux </xml>")
BrightScript Debugger> ? x.genXML(false)
<xml><tag> bar </tag></xml>
genXML should have reconstituted (more or less) the original but seems Foo and Qux have been lost in translation. Even Foo, that should've been the getText() to <xml>. Bugs?PS. in sample python libraries, "foo" will be made .text to <xml/>, "qux" is .tail to <tag/>, all is preserved/accessible.
PPS. i can think of alternative representation too, in which <xml/> will have 3 children, [0] being the string "foo" (or element with empty getName and "foo" as getText), then [1] is <tag> as usual, [2] the "qux" text (string or another empty tag). Then ifXMLElement.getText() will have to be clarified to "returns the first text contained in the element". This is less hacky and more to the spirit of xml but likely requires more changes in parser and may surprise some existing BRS code that is very stuck up on the sequence list it gets from getChildElements().
joetesta
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
09:15 PM
Re: XML Orphaned Text
"EnTerr" wrote:"joetesta" wrote:
I bet you can get it if you put another wrapper around it; assuming you need to maintain html compatibility I'd use <span>
No, the question was how to work with the XML as given, not to mangle it server-side.
It may be well formed XML and I may not have answered the question, but if you need this to happen now, I bet double or nothing my solution works.
aspiring
gonzotek
Visitor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
09:21 PM
Re: XML Orphaned Text
"joetesta" wrote:"EnTerr" wrote:"joetesta" wrote:
I bet you can get it if you put another wrapper around it; assuming you need to maintain html compatibility I'd use <span>
No, the question was how to work with the XML as given, not to mangle it server-side.
It may be well formed XML and I may not have answered the question, but if you need this to happen now, I bet double or nothing my solution works.
Sure, if you have control over the server side. What if the XML is coming from some embedded device or other server you have no control over?
Remoku.tv - A free web app for Roku Remote Control!
Want to control your Roku from nearly any phone, computer or tablet? Get started at http://help.remoku.tv
by Apps4TV - Applications for television and beyond: http://www.apps4tv.com
Want to control your Roku from nearly any phone, computer or tablet? Get started at http://help.remoku.tv
by Apps4TV - Applications for television and beyond: http://www.apps4tv.com
wlwest82
Visitor
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
09:23 PM
Re: XML Orphaned Text
"joetesta" wrote:
I bet you can get it if you put another wrapper around it; assuming you need to maintain html compatibility I'd use <span><xml>
<tag1 class="class1">
<a href="http://www.google.com">Google!</a>
<span>Some more text goes here</span>
</tag1>
</xml>
and see if you can get it with Parser.tag1.span.getText()
I ended up working around my problem using essentially this approach. In my actual XML, there was a <br /> tag after the </a> which I didn't need, so I used a roRegex to find all <br /> instances and replace them with the following: </tag1><tag1 class="text">. After the replace all, my new code looked like this (minus all the nice formatting):
<xml>
<tag1 class="class1">
<a href="http://www.google.com">Google!</a>
</tag1>
<tag1 class="text">
Some more text goes here
</tag1>
</xml>
I was then able to get to the text I needed with Parser.tag1[1].getText(). I still would be interested in how this is supposed to be done using the xml api.
PS-I don't have control over the server-side output. In a bit of an "Aha!" moment, I thought of the approach that Joetesta suggested.
joetesta
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-11-2014
09:24 PM
Re: XML Orphaned Text
"gonzotek" wrote:"joetesta" wrote:
It may be well formed XML and I may not have answered the question, but if you need this to happen now, I bet double or nothing my solution works.
Sure, if you have control over the server side. What if the XML is coming from some embedded device or other server you have no control over?
Then you'd be up a creek. Fortunately for wlwest82 that wasn't the case 🙂
aspiring
EnTerr
Roku Guru
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2014
12:56 PM
Re: XML Offal Text
"EnTerr" wrote:
... Simplifying the BRS example even more:BrightScript Debugger> x = CreateObject("roXMLElement")genXML should have reconstituted (more or less) the original but seems Foo and Qux have been lost in translation. Even Foo, that should've been the getText() to <xml>. Bugs?
BrightScript Debugger> x.parse("<xml> foo <tag> bar </tag> qux </xml>")
BrightScript Debugger> ? x.genXML(false)
<xml><tag> bar </tag></xml>
Somebody with Roku* name, please respond: How are such text handled with roXML?
Here is another example snippet ( http://www.xmlnews.org/docs/xml-basics.html#elements 😞
<p><person>Tony Blair</person> is <function>Prime Minister</function> of <location><country>Great Britain</country></location></p>
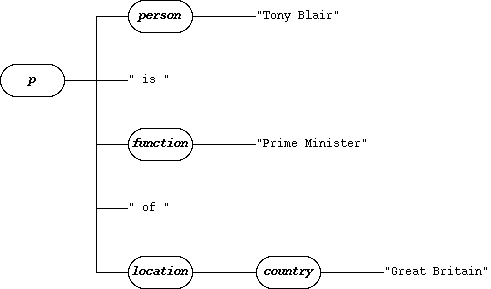
The texts in question are " is " and " of ". Where them at, after roXMLelement.parse()?
PS. for real-life examples, try NITF format of the news industry. E.g. http://www.iptc.org/std/NITF/3.2/exampl ... ishing.xml , <body.content> element
Need Assistance?
Welcome to the Roku Community! Feel free to search our Community for answers or post your question to get help.
Become a Roku Streaming Expert!
Share your expertise, help fellow streamers, and unlock exclusive rewards as part of the Roku Community. Learn more.
Become a Roku Streaming Expert!
Share your expertise, help fellow streamers, and unlock exclusive rewards as part of the Roku Community. Learn more.
